The robots exclusion protocol (REP), or robots.txt is a text file
webmasters create to instruct robots (typically search engine robots)
how to crawl and index pages on their website.
Although robots.txt lacks indexer directives, it is possible to set indexer directives for groups of URIs with server sided scripts acting on site level that apply X-Robots-Tags to requested resources. This method requires programming skills and good understanding of web servers and the HTTP protocol.
- https://moz.com/learn/seo/robotstxt
Cheat Sheet
Block all web crawlers from all content
User-agent: *
Disallow: /
Block a specific web crawler from a specific folder
Block a specific web crawler from a specific web page
User-agent: Googlebot
Disallow: /no-google/blocked-page.html
Sitemap Parameter
User-agent: *
Disallow:
Sitemap: http://www.example.com/none-standard-location/sitemap.xml
Optimal Format
Robots.txt needs to be placed in the top-level directory of a web server in order to be useful. Example: http://www.example.com/robots.txtWhat is Robots.txt?
The Robots Exclusion Protocol (REP) is a group of web standards that regulate web robot behavior and search engine indexing. The REP consists of the following:- The original REP from 1994, extended 1997, defining crawler directives for robots.txt. Some search engines support extensions like URI patterns (wild cards).
- Its extension from 1996 defining indexer directives (REP tags) for use in the robots meta element, also known as "robots meta tag." Meanwhile, search engines support additional REP tags with an X-Robots-Tag. Webmasters can apply REP tags in the HTTP header of non-HTML resources like PDF documents or images.
- The Microformat rel-nofollow from 2005 defining how search engines should handle links where the A Element's REL attribute contains the value "nofollow."
Robots Exclusion Protocol Tags
Applied to an URI, REP tags (noindex, nofollow, unavailable_after) steer particular tasks of indexers, and in some cases (nosnippet, noarchive, noodp) even query engines at runtime of a search query. Other than with crawler directives, each search engine interprets REP tags differently. For example, Google wipes out even URL-only listings and ODP references on their SERPs when a resource is tagged with "noindex," but Bing sometimes lists such external references to forbidden URLs on their SERPs. Since REP tags can be supplied in META elements of X/HTML contents as well as in HTTP headers of any web object, the consensus is that contents of X-Robots-Tags should overrule conflicting directives found in META elements.Microformats
Indexer directives put as microformats will overrule page settings for particular HTML elements. For example, when a page's X-Robots-Tag states "follow" (there's no "nofollow" value), the rel-nofollow directive of a particular A element (link) wins.Although robots.txt lacks indexer directives, it is possible to set indexer directives for groups of URIs with server sided scripts acting on site level that apply X-Robots-Tags to requested resources. This method requires programming skills and good understanding of web servers and the HTTP protocol.
Pattern Matching
Google and Bing both honor two regular expressions that can be used to identify pages or sub-folders that an SEO wants excluded. These two characters are the asterisk (*) and the dollar sign ($).- * - which is a wildcard that represents any sequence of characters
- $ - which matches the end of the URL
Public Information
The robots.txt file is public—be aware that a robots.txt file is a publicly available file. Anyone can see what sections of a server the webmaster has blocked the engines from. This means that if an SEO has private user information that they don’t want publicly searchable, they should use a more secure approach—such as password protection—to keep visitors from viewing any confidential pages they don't want indexed.Important Rules
- In most cases, meta robots with parameters
"noindex, follow"should be employed as a way to to restrict crawling or indexation. - It is important to note that malicious crawlers are likely to completely ignore robots.txt and as such, this protocol does not make a good security mechanism.
- Only one "Disallow:" line is allowed for each URL.
- Each subdomain on a root domain uses separate robots.txt files.
- Google and Bing accept two specific regular expression characters for pattern exclusion (* and $).
- The filename of robots.txt is case sensitive. Use "robots.txt", not "Robots.TXT."
- Spacing is not an accepted way to separate query parameters. For example, "/category/ /product page" would not be honored by robots.txt.
SEO Best Practice
Blocking Page
There are a few ways to block search engines from accessing a given domain:Block with Robots.txt
This tells the engines not to crawl the given URL, but that they may keep the page in the index and display it in in results. (See image of Google results page below.)Block with Meta NoIndex
This tells engines they can visit, but are not allowed to display the URL in results. This is the recommended method.Block by Nofollowing Links
This is almost always a poor tactic. Using this method, it is still possible for the search engines to discover pages in other ways: through browser toolbars, links from other pages, analytics, and more.Why Meta Robots is Better than Robots.txt
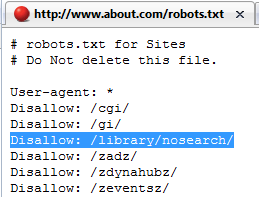
Below is an example of about.com's robots.txt file. Notice that they are blocking the directory /library/nosearch/.- https://moz.com/learn/seo/robotstxt



I love your own publish. It's great to determine a person explain in words in the center as well as clearness about this essential topic could be very easily noticed. Creative Banner
ReplyDelete